Saturday, December 10, 2005
Presentation at the EUMAS2005 Workshop in Brussels
In the 8th of December of 2005 I gave my first presentation in a workshop. You can find it clicking in the title of this post. Everything went well and at the end some of the participants congratulate me for the presentation. It was a pleasure to be able to speak with Juan Pavon from the Universidad Complutense Madrid - Spain, Danny Weyns from the Katholieke Universiteit Leuven - Belgium, Franziska Klugl and Manuel Fehler from the Institute of Artificial Intelligence and Applied Computer Science - University of Wurzburg - Germany, Pavlos Moraitis from the Dept. of Mathematics and Computer Science - University René Descartes-Paris 5 - France and Nikolaos I. Spanoudakis from Singular Software SA, Al. - Greece, among others. Thank you all.
Friday, November 25, 2005
Revised paper "A Multi-Agent System for Intelligent Monitoring of Airline Operations"
I have reviewed the paper for publication at the EUMAS 2005 Workshop, according to the reviewers. So, click on the title of this paper and take a look at the changes. Just to remember a previous post, the main comments of the reviewers were related with the fact that it is a very preliminar work and with some not very explained parts of the paper. I can do nothing, for now, regarding the fact of being a preliminar work but I have improved a lot of things regarding the less explained parts of the paper. It's well worth to read it again.
Wednesday, November 02, 2005
Paper Accepted at the EUMAS 2005 Workshop
I have received the information that my first paper "A Multi-Agent System for Intelligent Monitoring of Airline Operations" has been accepted to the EUMAS 2005 Workshop. I have had two positive reviews in three. The main comments are related with the fact that it is a very preliminar work and with some not very explained parts of the paper. Of course that all the comments made by the reviewers are very helpful and I will take that into consideration when sending the final version to the workshop.
I appreciate all the time that the reviewers took in commenting my paper.
If you have any other comments about this paper, please feel free to do so.
I appreciate all the time that the reviewers took in commenting my paper.
If you have any other comments about this paper, please feel free to do so.
Friday, October 07, 2005
Scalability: an important feature to achieve in a Multi-agent system
For commercial software systems, scalability it's an important feature to have. This gives the customer the possibility of expand the system according to present and future demand, without having to stop and start again. Nowadays many business work 24 hours a day 7 days a week. To stop is not an option. If we want MAS to have success in a commercial environment we need to build scalable MAS. For my MAS, the fact of having a hierarchical organization of agents to solve the crew recovery problem and another to solve the aircraft recovery problem, will allow at a certain extend, the scalability that I refer in the beginning of this post.
As an example, suppose that we deploy the system with 3 agents, each one implementing a different algorithm for crew recovery. Later on, the customer found that the system is not able to solve some specific problems or that a new and much improved algorithm has been discovered that deals better with those kinds of problems. In this situation, we just need to develop a new agent that implements the new or improved algorithm and attached it to the existing organization and everything should be fine. We can do that without interrupting the MAS.
Another possible situation is the following: suppose that we found the need to have a new sub-organization, at the same level of crew and aircraft recovery, to deal with a different kind of problems (for example, passenger recovery). To be a scalable system, we just need to build the new sub-organization, with all the necessary agents to solve that kind of specific problems, and attach it to the existing MAS. However, at this level and according to our first draft, the organization is not hierarchical. How to solve this problem? How can we prepare our system so that the new organization captures the problems that should be solved by them and the other organizations ignore that kind of problems? Do you think it will be possible to have some kind of learning, at this level, so that the MAS learns how to solve unexpected problems? As usual, if you have any comments, please do so, using the above option for that.
As an example, suppose that we deploy the system with 3 agents, each one implementing a different algorithm for crew recovery. Later on, the customer found that the system is not able to solve some specific problems or that a new and much improved algorithm has been discovered that deals better with those kinds of problems. In this situation, we just need to develop a new agent that implements the new or improved algorithm and attached it to the existing organization and everything should be fine. We can do that without interrupting the MAS.
Another possible situation is the following: suppose that we found the need to have a new sub-organization, at the same level of crew and aircraft recovery, to deal with a different kind of problems (for example, passenger recovery). To be a scalable system, we just need to build the new sub-organization, with all the necessary agents to solve that kind of specific problems, and attach it to the existing MAS. However, at this level and according to our first draft, the organization is not hierarchical. How to solve this problem? How can we prepare our system so that the new organization captures the problems that should be solved by them and the other organizations ignore that kind of problems? Do you think it will be possible to have some kind of learning, at this level, so that the MAS learns how to solve unexpected problems? As usual, if you have any comments, please do so, using the above option for that.
Monday, October 03, 2005
A Brief Summary of the GAIA Methodology
During my study I have prepared a brief summary of the GAIA methodology. For those interested, please click in the title of this blog to see the PDF with the presentation.
This presentation was based in the following paper:
Developing Multi-Agent Systems: The GAIA Methodology
F. Zambonelli, N. Jennings, M. Wooldridge
ACM, Vol. 12, N. 3, July 2003
Other interesting papers referenced in the above one are:
Towards requirements-driven information systems engineering: The TROPOS project
J. Castro, M. Kolp, J. Mylopoulos
Inf. System Vol. 27 N. 6, June 2002.
From object-oriented to goal-oriented requirements analysis
J. Mylopoulos, L. Chung, E. Yu
ACM Vol. 42, N. 1, January 1999
Representing agent interaction protocols in UML
J. Odell, H. Parunak, C. Bock
Proc. 1st Int. Work. AOSE, Vol. 1957, 2001
Agent UML: A formalism for specifying multiagent software systems
B. Bauer, J. P. Muller, J. Odell
Int. Journal Soft. Eng. Knowl. Eng. Vol. 11 N. 3, April 2001
As usual, if you want to share any comments or ideas on these, please feel free to use the comments link above this post.
This presentation was based in the following paper:
Developing Multi-Agent Systems: The GAIA Methodology
F. Zambonelli, N. Jennings, M. Wooldridge
ACM, Vol. 12, N. 3, July 2003
Other interesting papers referenced in the above one are:
Towards requirements-driven information systems engineering: The TROPOS project
J. Castro, M. Kolp, J. Mylopoulos
Inf. System Vol. 27 N. 6, June 2002.
From object-oriented to goal-oriented requirements analysis
J. Mylopoulos, L. Chung, E. Yu
ACM Vol. 42, N. 1, January 1999
Representing agent interaction protocols in UML
J. Odell, H. Parunak, C. Bock
Proc. 1st Int. Work. AOSE, Vol. 1957, 2001
Agent UML: A formalism for specifying multiagent software systems
B. Bauer, J. P. Muller, J. Odell
Int. Journal Soft. Eng. Knowl. Eng. Vol. 11 N. 3, April 2001
As usual, if you want to share any comments or ideas on these, please feel free to use the comments link above this post.
A Multi-Agent System for Intelligent Monitoring of Airline Operations
I have finished my first paper regarding the subject of my thesis. This paper has been submitted to EUMAS 2005 (Third European Workshop on Multi-Agent Systems). At present date I do not know if it is going to be accepted. However, I would like to give you a roadmap of the paper and share with you some of the ideas presented. If you want to read the full paper, just click on the title of this post. For an introduction to the subject of Airline Operations Control and all related problems (Crew Recovery, Aircraft Recovery, Passenger recovery, etc.) I recommend the reading of Section 1 - Introduction and of Section 2 - The Airline Scheduling Problem. If you want to know what methodologies and tools we are using, just read section 3. Section 4 - Vision and Scope of our MAS states the vision for this project, including the goals we proposed to achieve. We also point out some of the problems that arise during airline operations control. Section 5 - Analysis and Proposed Architecture is the most important one. Here we present for hypothesis and predictions related with the most relevant parts of our work, namely:
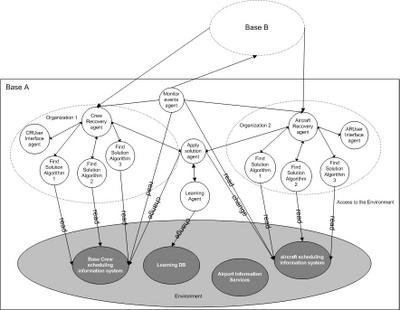
Finally, Section 6 - Future work, gives an overview of what we would like to explore in the future. So, click the title of this post, read the document and comment the other related posts.
- We hypothesize that the main objective of airline operation (that is, flights always on
time) will be much easier to achieve (that is, less flights delayed) if we take advantage of the fact that the crew members belong to different bases. We predict that if we solve the problems first with local resources and then with non-local resources, the solutions to the eventual problems will be much faster to find and, in some cases, the non-local solutions might be the only solution available. - Second, we hypothesize that the use of different algorithms to solve the same problem (in crew and aircraft recovery) will improve the achievement of the main objective of the crew and aircraft recovery process (that is, to always find the better solution regarding “ensuring every flight has a crew” and “ensuring that all flights are on time”, respectively). We predict that using different algorithms (genetic algorithms, heuristic, etc.) in comparison with using always the same algorithm, to solve the same problem, will permit to (1) always find the best solution (according to the criteria defined by the company) and (2) to always find a solution, especially taking into account the fact that we might benefit from solutions presented by other bases, as stated in the first hypothesis.
- Third, we hypothesize that the implementation of a learning mechanism that will learn from the use of crew members (in comparison with the previous and published schedule and in characterizing specific situations) will permit a better use of the resources (especially crew members) in future schedules. We predict that, for example, if we learn the real use of stand by crew members in each month and in specific situations, will allow adjusting the stand by roster in similar months or similar situations of future schedules, permitting to release crew members to be schedule to flights (crew members are one of the most expensive resources in an airline company).
- Forth, we hypothesize that if we extend the learning mechanism to learn the profile of each crew member, regarding his/her preferences, will increase the level of satisfaction of them. We predict that applying the learned profile of each crew member in future schedules of corresponding months will produce a roster that will achieve the goals of the airline company and, at the same time, the satisfaction of the crew members. Increasing the level of satisfaction of a crew member will decrease the crew member’s absence to work.
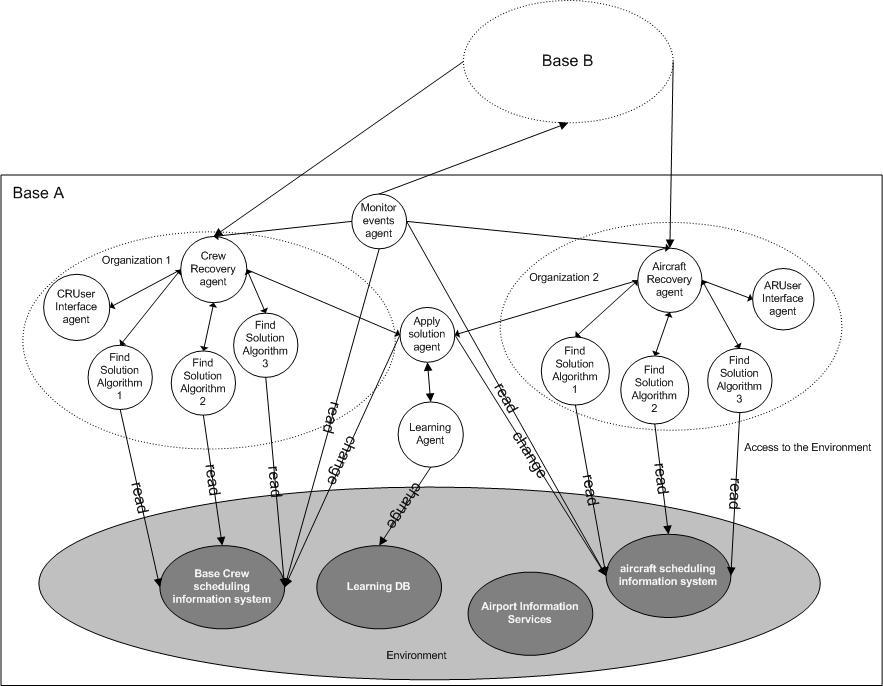
Finally, Section 6 - Future work, gives an overview of what we would like to explore in the future. So, click the title of this post, read the document and comment the other related posts.
Tuesday, September 27, 2005
Microsoft Research eScience Workshop 2005
Next week (6th and 7th of October) I will attend the Microsoft Research eScience workshop 2005 in Redmond, Washington, USA. According to the workshop site "this workshop provides a unique opportunity to learn and affect what is happening in the realm of data intensive scientific computing within Microsoft. Attendees will learn first hand from early adopters using Microsoft Windows, Microsoft .NET, Microsoft SQL Server, and Web services in these problem spaces, as well as explore in-depth how modern database technologies and techniques are being applied to scientific computing. By providing a forum for scientists and researchers to share their experiences and expertise with the wider academic and research communities, this workshop will foster collaboration, facilitate the sharing of software components and techniques, and establish a vision for Microsoft Windows and .NET in data intensive scientific computing."
Because I work with all the above mencioned technologies, I'm interested in studying how I can use or extend them regarding the subject of my thesis. Specially I'm interested in research how I can develop "intelligent" web services that can be helpful in Multi-Agent Systems. Those web services should be able to do more than "connect" several different systems. They should have an "intelligent" behavior when participating in those "connections" and/or in completing any task.
I'm interested in your opinion regarding this subject. Do you have any questions that you would like to post? Do you agree or disagree with my point of view? Do you think that Web Services technology can have an important place in Muit-agent systems or do you think that we do not need them.
Please use the comments below and put all the questions and/or observations that you want. I will use them during the workshop to present this subject to the other attendess.
Because I work with all the above mencioned technologies, I'm interested in studying how I can use or extend them regarding the subject of my thesis. Specially I'm interested in research how I can develop "intelligent" web services that can be helpful in Multi-Agent Systems. Those web services should be able to do more than "connect" several different systems. They should have an "intelligent" behavior when participating in those "connections" and/or in completing any task.
I'm interested in your opinion regarding this subject. Do you have any questions that you would like to post? Do you agree or disagree with my point of view? Do you think that Web Services technology can have an important place in Muit-agent systems or do you think that we do not need them.
Please use the comments below and put all the questions and/or observations that you want. I will use them during the workshop to present this subject to the other attendess.
Friday, September 02, 2005
How to write a research paper
During my summer holidays I found a very interesting article ("So You Want to Write a Research Paper", Studyworks 2002) about this subject. This article belongs to a class subject for USA high school students. This fact by itself is amazing, especially when compared with what happens in Portuguese schools. My first contact with research papers was only during my master degree classes. How can we compete with these countries? It's impossible!
Based on this article in a free adaptation, I'm going to do a draft for a possible research paper of my thesis subject. I hope this will help me and all the readers of my blog.
The scientific method is helpful to remember when setting out to write a research paper. It's a systematic way of approaching and analyzing the natural world (or the domain of your research).
Now you need to define the prediction. Following the example, it could be: "When compared with a single algorithm approach the proposed system should be able to solve satisfactorily (i.e., according to the criteria defined by the users) all type of problems. Namely, it should be able to find solutions to problems that the single approach cannot find. Some kind of synergy should happen".
Before starting to test the prediction it might be a good idea to do some follow-up reading and research. You should start by thinking where you'll find information about your topic. Is there a book or two about the subject? Should you check scientific literature for information? Make a list of sources to check before entering the library or the Internet. Keep a list of potential sources. Then go and skim them quickly. Cross-off sources from your list that you don't think will be helpful. Keep track of the good ones for later. After this step Gathering and Organizing Information is the next phase.
Now that you have a list of good potential sources you need to read them. You have a lot of information to keep track of, and you'll need to know what facts and ideas come from that source. The best way to track information is to record bibliographic information as you go, and to take notes on each source as you read it. You might use a word processor or another mechanism to do this. Remember to record the information needed to find the source again plus the biographic information (author's name, title of the book/article, publication information) and, of course, the notes you have taken during the reading. While you take notes it is mandatory to use quotes when you copy text directly from a source and give credit to the author. If you paraphrase another author in your paper you also need to give credit to the author.
If you are writing a research paper based on an experiment, you have some additional things to consider when gathering and organizing information. That's the so called "Materials, Methods and Data" that raises the following questions:
After performing the experiment for testing your prediction, using all the previous advices, you need to interpret the results and accept or reject your hypothesis. This will be the conclusion of your work. As a summary:
Title
Should be specific enough that your reader knows immediately what kind of information will find on the paper, but not so specific that you include unnecessary information. Should be relatively short, usually not more than 70 or 100 characters. Write it in as clear and concise manner as possible, using a professional, rather than conversational tone.
Abstract
Always, always, always save writing the abstract until after you've written the rest of your paper. The abstract is an extremely concise synthesis of your entire paper - it contains the major question, or hypothesis, your basic approach to answering that question, key results and/or data, and a brief conclusion about what you discovered. Abstracts are about one-paragraph long or one-half page of double-spaced text. The abstract is what researchers scan when they find a paper they think might be interested in.
Introduction
This is your chance to explain to your reader exactly why you did the research or experiment that you did. By laying out your ideas on in a clear and orderly fashion, your reader will follow your logic and anticipate what happens throughout the rest of your paper. Be sure to include the following:
Materials and Methods
In this section you tell your reader exactly what you did to test your hypothesis, but don't write unnecessary detail. You should provide enough description for your reader to be able to repeat your experiment just as you did it, without writing every single thing that you did, especially when some steps or procedures are obvious. Remember the following when writing this section:
Results
Here you report the results of your experiment (or, if appropriate, your library research). The most important thing to remember in this section is that it should be strictly about your observed results, not about how you may be interpreting them (saved that for discussion). This is the only section in which you should include graphs or tables. And every graph, figure, or table you include should be referred to in the text of your results section. Remember the following:
Here's your chance to interpret your results (or discuss what you found in your library research). Start with a specific conclusion about your results, and work your way out to a broader overview of what those results mean. Consider the following:
Literature Cited
If you've kept track of all your references then all you have to do now is start a new page with the heading "References", alphabetize your sources and list them in the correct form. Remember to include only the sources that you actually used as you wrote your paper - the ones you cite within the text itself. An example of a correct form is the following: Author's name. Title of the book/article. Publication information. Example:
Gibaldi, J. MLA Handbook for writers of Research Papers. 4th ed. New York, NY. The Modern Language Society of America, 1995.
I hope this will be helpful to you. If you have any comments, please feel free to use the option comments at the end of this post, to write your comments and/or suggestions.
Based on this article in a free adaptation, I'm going to do a draft for a possible research paper of my thesis subject. I hope this will help me and all the readers of my blog.
The scientific method is helpful to remember when setting out to write a research paper. It's a systematic way of approaching and analyzing the natural world (or the domain of your research).
- First, observe some aspect of the natural world or of your domain (either in nature/local or by reading about it in the library).
- Then make a testable hypothesis to explain your observations and, based on that hypothesis, make a prediction about how future observations should appear.
- Next, test your prediction by searching for evidence - either by performing experiments or by additional observation or literature review.
- Finally, after interpreting the results of your testing, accept or reject your hypothesis.
Now you need to define the prediction. Following the example, it could be: "When compared with a single algorithm approach the proposed system should be able to solve satisfactorily (i.e., according to the criteria defined by the users) all type of problems. Namely, it should be able to find solutions to problems that the single approach cannot find. Some kind of synergy should happen".
Before starting to test the prediction it might be a good idea to do some follow-up reading and research. You should start by thinking where you'll find information about your topic. Is there a book or two about the subject? Should you check scientific literature for information? Make a list of sources to check before entering the library or the Internet. Keep a list of potential sources. Then go and skim them quickly. Cross-off sources from your list that you don't think will be helpful. Keep track of the good ones for later. After this step Gathering and Organizing Information is the next phase.
Now that you have a list of good potential sources you need to read them. You have a lot of information to keep track of, and you'll need to know what facts and ideas come from that source. The best way to track information is to record bibliographic information as you go, and to take notes on each source as you read it. You might use a word processor or another mechanism to do this. Remember to record the information needed to find the source again plus the biographic information (author's name, title of the book/article, publication information) and, of course, the notes you have taken during the reading. While you take notes it is mandatory to use quotes when you copy text directly from a source and give credit to the author. If you paraphrase another author in your paper you also need to give credit to the author.
If you are writing a research paper based on an experiment, you have some additional things to consider when gathering and organizing information. That's the so called "Materials, Methods and Data" that raises the following questions:
- What exactly did you do in order to test your hypothesis?
- What materials did you need?
- How did you organize the data you collected?
After performing the experiment for testing your prediction, using all the previous advices, you need to interpret the results and accept or reject your hypothesis. This will be the conclusion of your work. As a summary:
- Define the topic of your research. Small, concrete and related with your domain of research. If necessary do some initial research.
- Define a testable hypothesis based on your topic.
- Based on that hypothesis make a prediction easily testable.
- Do some follow-up reading and research before starting to test the prediction.
- Define a good Gathering and Organizing Information System.
- Keep a "Lab Notebook" to help to keep the "Materials, Methods and Data".
- Write the conclusion. Interpret the results, accept or reject the hypothesis.
Title
Should be specific enough that your reader knows immediately what kind of information will find on the paper, but not so specific that you include unnecessary information. Should be relatively short, usually not more than 70 or 100 characters. Write it in as clear and concise manner as possible, using a professional, rather than conversational tone.
Abstract
Always, always, always save writing the abstract until after you've written the rest of your paper. The abstract is an extremely concise synthesis of your entire paper - it contains the major question, or hypothesis, your basic approach to answering that question, key results and/or data, and a brief conclusion about what you discovered. Abstracts are about one-paragraph long or one-half page of double-spaced text. The abstract is what researchers scan when they find a paper they think might be interested in.
Introduction
This is your chance to explain to your reader exactly why you did the research or experiment that you did. By laying out your ideas on in a clear and orderly fashion, your reader will follow your logic and anticipate what happens throughout the rest of your paper. Be sure to include the following:
- Observations - What did you observe that caused you to begin this study? What brought you to this area of inquiry? Start with a general observation, and then get more specific.
- Hypothesis - Based on your observations, what is your hypothesis?.
- Prediction - What is the prediction(s) that accompanies your hypothesis?.
- Expected results - As you conclude your introduction, your most specific pieces of information will be your expected results. Always write what you expected to see prior to beginning your research.
Materials and Methods
In this section you tell your reader exactly what you did to test your hypothesis, but don't write unnecessary detail. You should provide enough description for your reader to be able to repeat your experiment just as you did it, without writing every single thing that you did, especially when some steps or procedures are obvious. Remember the following when writing this section:
- Explain how you tested your hypothesis - This is your main goal, and is best done by writing what you did so that another person could repeat your procedure.
- Write in paragraph form - Don't make a list of procedures or equipment.
- Write in past tense - You've done the work and it is now completed.
- Decision making - Include a paragraph on data analysis and how you arrived at your decisions regarding your hypothesis(es). If you've used statistical tests make it clear how your statistical hypothesis relates to your experimental hypothesis. If you didn't use statistical tests, how did you arrive at decisions about the experiment you performed? Give enough information that someone could repeat what you've done. Don't explain how to do basic statistics. Do state what statistical tests you used.
Results
Here you report the results of your experiment (or, if appropriate, your library research). The most important thing to remember in this section is that it should be strictly about your observed results, not about how you may be interpreting them (saved that for discussion). This is the only section in which you should include graphs or tables. And every graph, figure, or table you include should be referred to in the text of your results section. Remember the following:
- First - Show actual data (usually transformed into measures of mean and variance). You'll generally do this within the text, and may also include graphs or tables as appropriate.
- Second - Include results of any statistical tests.
- Third - State whether your hypothesis was accepted or rejected.
- Write in past tense - You've already found the results.
- Tables, Graphs, and Figures - Include these only in the results section. Never include them without some explanation in your text. Organize them in the order that you are presenting the results. Always clearly and concisely label tables, figures and graphs.
- Don't interpret the results - You'll interpret your results in the discussion section. The results section is simply a review of what you found.
Here's your chance to interpret your results (or discuss what you found in your library research). Start with a specific conclusion about your results, and work your way out to a broader overview of what those results mean. Consider the following:
- Conclusions - Did you accept or reject you hypothesis. What does this allow you to conclude about your questions? Is this what you expected to see, or is it very different from what you expected?
- Interpretation - If your results were not what you expected, consider possible reasons for this. Do you need to collect more data? Did anything go wrong while you performed the experiment? Were there problems with the methods that may have made it difficult to test your hypothesis effectively? Does the whole question need to be reexamined based on your unexpected results? If your results were what you expected, what is the significance of this? How do your results fit in with what other researchers have found? Do your results and conclusions generate new questions and predictions?
- The bigger picture - What have you, and the community who might read your paper, gained from this research? How does it fit in with what is already known about the area or topic your worked in?
Literature Cited
If you've kept track of all your references then all you have to do now is start a new page with the heading "References", alphabetize your sources and list them in the correct form. Remember to include only the sources that you actually used as you wrote your paper - the ones you cite within the text itself. An example of a correct form is the following: Author's name. Title of the book/article. Publication information. Example:
Gibaldi, J. MLA Handbook for writers of Research Papers. 4th ed. New York, NY. The Modern Language Society of America, 1995.
I hope this will be helpful to you. If you have any comments, please feel free to use the option comments at the end of this post, to write your comments and/or suggestions.
Thursday, September 01, 2005
How to deal with a multi-user and relational database environment
Most of the papers I have read, even the ones from OR, related with Crew Recovery or Crew Scheduling problems among others, present the solution having the data represented in a matrix and/or vectors. Unfortunately, most of the environments that exist in the airline companies have the data in relational databases and use multi-user systems. To apply those solutions we need to transfer the data to the proposed representation, apply the algorithm and, then, put the data back in the relational database (supposing that we have enough hardware to support all the information in memory). This seems feasible but what happens if someone or some system changes any of the data used for finding the solution, during the time the algorithm is working? To not allow any change during the time the algorithm is working is not feasible. We have to use algorithms that will be able to be applied to relational databases and, when applying the solutions, we need to check if everything is as before.
Any ideas on how to approach this problem? Please feel free to drop any comments/suggestions using the comments options at the end of this post. Thank you.
Any ideas on how to approach this problem? Please feel free to drop any comments/suggestions using the comments options at the end of this post. Thank you.
Wednesday, July 27, 2005
Final Thesis Proposal Presented
Today I have finished my final thesis proposal report. This report also includes the state-of-the-art related with the subject of my thesis proposal. At 5:00 pm I will have to present this report to my colleagues, teachers and supervisor. After the presentation I will post a summary of the most important features, methodologies and tools of Roster Tracker, the name of the proposed system. For now you can have access to the full report, presentation and documents referenced in my thesis proposal through the following links:
Thesis Proposal: Roster Tracker - An Intelligent Way of Monitoring Airline Operations
Thesis Proposal Presentation: Roster Tracker
Thesis Proposal: Roster Tracker - An Intelligent Way of Monitoring Airline Operations
Thesis Proposal Presentation: Roster Tracker
Tuesday, July 19, 2005
Comments about Michael N. Huhns paper "Software Development with Objects, Agents and Services"
During the reading of this paper I was able to spot some interesting ideas to explore during my thesis. I'm going tho share with all of you those ideas. In this post I will discuss only a few. If you want to read the original document just click the title of this post. If your prefer to read my detailed notes, click here.
In this paper Michael Huhns talks about SOC - Service Oriented Computing. According to him "it is a process of discovering and composing the proper services to satisfy a specification, whether the specification is expressed in terms of goal, a workflow (tasks), or some other model". One of the challenges for SOC is that it is necessary an Organization of Services in the repository (of services), something that does not happen nowadays. Among other things, it is necessary an infrastructure to enable discovery of pertinent objects. I know that there are some research related with this subject (for example X. Dong, J. Madhavan and A. Halevy paper "Mining Structures for Semantics"), however, I think we could try a different approach: consider a repository of web services meta-data and, given a specific service we are looking for, characterize that service in terms of meta-data and, according to the k-NN ranking method, receive a recommended ranking of existing web services to use. A mandatory characteristic of the meta-data has to be an excellent semantic definition of the web service.
The main focus of the paper is about Consensus Software, ie, the approach proposed by Michael. It seems to me that he is reflecting about a society of agents in a large scale, where an agent, after arriving to that society, could identify other agents to help him in realizing the tasks he has to fulfill. A lot of questions regarding security and so, arise from this moment on. But I think it is a very interesting vision.
Another interesting thought is that "as societies attempt to coordinate and control their members use of utilities and resources, individuals should have a means to influence the coordination and control based on their preferences...". For me the concept of democratization in software it's something important to explore: to leave the centralized perspective and allow users express their preferences. For this to be possible it is necessary to define objectives and constraints and, then, let the users express themselves. In the crew-scheduling problem, for example, this would allow the crewmembers to express their choice for the monthly crew roster. The objective would be to have Active systems that, after learning the user's preferences, could intercede on behalf of the user, when the decision has to be made.
Other things that might be useful for my thesis: Redundancy and Robustness. Just like in a cockpit of an airplane there are some replicated instruments and some of them using different technology, I could use different agents that try to solve the same problem using different algorithms. Using this approach I can increase the robustness of the application and, if I use a good criteria, I will have the opportunity to choose the best one among the several solutions.
Two more things before finish:
In this paper Michael Huhns talks about SOC - Service Oriented Computing. According to him "it is a process of discovering and composing the proper services to satisfy a specification, whether the specification is expressed in terms of goal, a workflow (tasks), or some other model". One of the challenges for SOC is that it is necessary an Organization of Services in the repository (of services), something that does not happen nowadays. Among other things, it is necessary an infrastructure to enable discovery of pertinent objects. I know that there are some research related with this subject (for example X. Dong, J. Madhavan and A. Halevy paper "Mining Structures for Semantics"), however, I think we could try a different approach: consider a repository of web services meta-data and, given a specific service we are looking for, characterize that service in terms of meta-data and, according to the k-NN ranking method, receive a recommended ranking of existing web services to use. A mandatory characteristic of the meta-data has to be an excellent semantic definition of the web service.
The main focus of the paper is about Consensus Software, ie, the approach proposed by Michael. It seems to me that he is reflecting about a society of agents in a large scale, where an agent, after arriving to that society, could identify other agents to help him in realizing the tasks he has to fulfill. A lot of questions regarding security and so, arise from this moment on. But I think it is a very interesting vision.
Another interesting thought is that "as societies attempt to coordinate and control their members use of utilities and resources, individuals should have a means to influence the coordination and control based on their preferences...". For me the concept of democratization in software it's something important to explore: to leave the centralized perspective and allow users express their preferences. For this to be possible it is necessary to define objectives and constraints and, then, let the users express themselves. In the crew-scheduling problem, for example, this would allow the crewmembers to express their choice for the monthly crew roster. The objective would be to have Active systems that, after learning the user's preferences, could intercede on behalf of the user, when the decision has to be made.
Other things that might be useful for my thesis: Redundancy and Robustness. Just like in a cockpit of an airplane there are some replicated instruments and some of them using different technology, I could use different agents that try to solve the same problem using different algorithms. Using this approach I can increase the robustness of the application and, if I use a good criteria, I will have the opportunity to choose the best one among the several solutions.
Two more things before finish:
- Agent-based Web Services.
According to Michael they are the answer for the communication among the heterogeneous objects in such a "distributed active-object architecture". I should analyze the new developments in JADE plataform regarding implementation of Web Services and study how to use them in my thesis. - Agent-oriented methodologies.
Agent UML, MAS-CommonKADS and GAIA, are the most investigated and applied. I should consider one of them to use in my thesis.
This concludes part of my reflection regarding this paper. If you want to read my detailed notes, just click here.
Friday, July 08, 2005
Neural Networks Summer School 2005

During this week (4 to 8th of July 2005) I participate in the NN Summer School 2005 in ISEP, Porto. My goal was to learn more about NN in particular and Learning in general and, of course, to have some inspiration and ideas to be used in my thesis. My "Moleskine" is full of notes that I was able to take during the school. Lectures from Chris Bishop and Juergen Schmidhuber as well as from many others were really inspiring. In the next few weeks I will post some of them here, just in time for my Thesis Project presentation at the end of this month.
Wednesday, April 06, 2005
Thesis project class - Ideas for brainstorming
Until the 26th of July of 2005 and during the thesis project class I need to research the state of the art of my research area. I also have to create a thesis work proposal and present both in a report and in a presentation to the students and teachers. After a brief meeting with my supervisor, Professor Eugénio Oliveira and to be able to accomplish those goals I think it is better to sub-divide my thesis in the following areas and research the state of the art for each of them:
Tasks to be performed until the next meeting (18th April 2005 at 4 pm)
- Multi-agent systems (MAS)
Systems architecture, Agent architecture, cooperation, competition. - Methodologies for MAS
Gaia, Mase and AUML. Create a summary including advantages and disadvantages and current status. - JADE
What's new? Alternatives? Implementation of Jade in .NET? - Crew-scheduling
What are the different solutions that have been already implemented. Is it possible to implement them for test and comparison with our solution? Create a summary of the existing ones, their requirements and applications including the advantages and disadvantages of each one. - Advanced Search Methods
Constraint Logic Programming, Genetic Algorithms, Simulated Annealing, Heuristics and many others. Create a summary of the existing ones, their requirements and applications including the advantages and disadvantages of each one. The idea is to choose the right ones to use. - Learning
Which are the methods available? Create a summary of all of them with requirements, applications, advantages and disadvantages. - Ontology
Is it necessary to do anything new and different or are we just going to use a ontology that we will define?
- Generation of partial solutions and how to cooperate in these situations?
Tasks to be performed until the next meeting (18th April 2005 at 4 pm)
- Research in the web and bibliography of the above areas.
- Obtain a data structure and a set of data regarding flights, parings, roster, etc., that are used in TAP.
Tuesday, April 05, 2005
Class Documents On-line
The reports and other documents related with the classes of my master degree have been posted on-line. Use the link section to check them out.
Sunday, April 03, 2005
The final countdown to start my Master Degree thesis
Today I gave the first step in preparing for my Msc Thesis with the creation of this blog. Here I will report the doubts, problems, solutions, research and other related items. A possible title for my thesis is "Roster Tracker - An Intelligent Way of Monitoring and Solving Problems Related with Airline Crewmembers Activity". Stay tuned and return to this blog often!
Subscribe to:
Posts (Atom)
